Databricks Lakehouse – Tietoallas ja tietovarasto samassa paketissa

Databricks on useimmille data-alan ammattilaisille tuttu palveluntarjoaja, ja Epicalilla olemme hyödyntäneet Databricksiä tiedonhallinnan ja analytiikan ratkaisuissa jo vuosia. Databricks löytyy sekä Microsoftin Azuren, Amazonin AWS:n että Googlen GCP:n pilvipalvelutarjoomasta. Se on tarkoitettu tiedon skaalautuvaan hallintaan, -jalostukseen ja hyödyntämiseen. Palvelu tarjoaa yhden alustan alla työkaluja perinteisempään tiedonhallintaan (esim. tietovarastot), isojen datamassojen säilytykseen ja arkistointiin (tietoaltaat), sekä edistyneempiin koneoppimis- ja tekoälysovelluksiin. Databricks pohjautuu avoimen lähdekoodin teknologioihin ja kehittyy jatkuvasti ja nopeasti.
Tämän kirjoituksen aiheena on Databricksin edistämä "Data Lakehouse" -konsepti, joka lupaa yhdistää tietoaltaan ja tietovaraston tarjoten molempien parhaat puolet. Etuna lakehousessa on, että erillisiä tietoallas- ja tietovarastoympäristöjä ei tarvita, vaan samaa alustaa ja dataa voidaan hyödyntää kummankin ratkaisun tyypillisissä käyttötarkoituksissa. Siten säästetään datan säilytykseen ja prosessointiin käytettäviä resursseja ja kehitykseen kuluvaa työaikaa. Lisäksi data säilytetään avoimen lähdekoodin Parquet tiedostoissa, joten ne on helppoa siirtää palveluntarjoajalta toiselle tai vaikkapa omalle palvelimelle. Uskomme, että lakehouse-arkkitehtuuri tarjoaa varsin hyvän vaihtoehdon pitkäaikaiseksi, joustavaksi ja skaalautuvaksi tiedonhallintaratkaisuksi analytiikkaa varten.
Miten data lakehouse syntyi?
Tietovarastoilla on jo vuosikymmeniä pitkä historia analytiikkaratkaisujen lähteenä, mutta isojen, reaaliaikaisesti päivittyvien ja strukturoimatontakin dataa sisältävien tietolähteiden aikana perinteinen tietovarasto ei enää välttämättä taivu kaikkiin käyttötapauksiin. Tietoallas-konsepti syntyi viime vuosikymmenellä vastaamaan niihin, mutta jo melko nopeasti huomattiin, että tässäkin ratkaisussa oli puutteensa. Esimerkiksi ACID-transaktiotuen puuttuminen, suorituskykyhaasteet analytiikkatyökuormissa sekä datan mallintamisen ja yhdistelemisen vaikeus pitivät perinteiset tietovarastot ajankohtaisina tietoaltaiden rinnalla.
Usein päädyttiin rakentamaan molemmat, sillä esimerkiksi Apache Spark-teknologiaan pohjautuva tietoallas soveltuu hyvin todella isojen ja strukturoimattomien datamassojen käsittelyyn datatiede- ja koneoppimisnäkökulmasta, kun taas SQL-pohjaiset tietovarastokannat ovat parempia strukturoidun datan yhdistelyssä esimerkiksi dimensionaalista tietomallia hyödyntäviä raportointityökaluja varten. Täten ensin vietiin data tietoaltaaseen arkistointia ja mahdollisia datatieteilijöiden käyttötapauksia mahdollistamaan, ja sitten kopioitiin data tietovarastoon relaatiotietokantaa vaativia työkuormia, kuten raportointia, varten. Tällainen arkkitehtuuri kuitenkin johti datan replikointiin, kahden ympäristön yhtäaikaiseen ylläpitoon ja kehitykseen sekä siihen, että esimerkiksi data-analyytikot ja -tieteilijät joutuivat usein työskentelemään eri alustoilla – tai käyttämään molempia alustoja lähteenä.
Kuva 1. Tietovarasto- ja lakehouse-arkkitehtuurien vertailu.
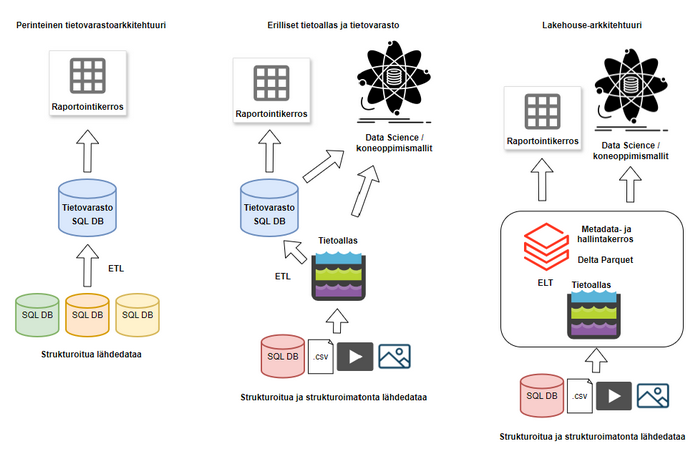
Lakehousen tulevaisuus
Lakehouse syntyi vastauksena edellä kuvattuun kahden erillisen ympäristön ongelmaan. Arkkitehtuuri mahdollistaa kustannustehokkaasti isojenkin datamassojen säilytyksen ja prosessoinnin, reaaliaikaisen datan päivittymisen, strukturoidun ja strukturoimattoman datan käsittelyn, perinteisemmät analytiikka- ja raportointikäyttötapaukset SQL-kieltä hyödyntämällä, edistyneemmät koneoppimis- ja tekoälyratkaisut, hyvän ja skaalautuvan suorituskyvyn sekä yhden alustan, jolla hallinnoida käyttöoikeuksia ja pääsyä dataan.
Vaikka Databricks Lakehouse ymmärtää SQL:ää ja käyttökokemus ei juuri eroa SQL-tietokannasta, ei data silti ole fyysisesti SQL-tietokannassa, vaan Parquet-tiedostoina Delta Lake-teknologiaa käyttävässä tietoaltaassa. Delta Lake mahdollistaa Parquet-tiedostoille ACID-transaktiotuen, joka on aiemmin ollut perinteisen SQL-tietokantaan perustuvan tietovaraston isoimpia hyötyjä tietoaltaaseen nähden. Lisäksi markkinoilla on tarjolla niin sanottuja visuaalisella käyttöliittymällä varustettuja ”low code”-ETL-työkaluja, mikäli kehittäjä ei halua rakentaa latauksia (pelkästään) koodipohjaisesti.
Uskosta lakehouse-konseptin toimivuuteen kertonee sekin, että kumppanit ja kilpailijat kuten Microsoft ja Snowflake panostavat vastaavanlaisesti kaikki työkuormat yhden alustan alla mahdollistaviin palveluihin – Microsoftin uusi tuote Fabric hyvänä esimerkkinä. Taustalla vaikuttaa tarve yksinkertaistaa tietoarkkitehtuureja ja siten palvelujen ja työkalujen hallinnointia sekä vähentää turhaa datan replikointia ympäristöstä toiseen.
Selkeitä lakehousen etuja ovat helppous, joustavuus, skaalautuvuus ja monipuolisuus. Lakehouse-ratkaisussa analytiikkakerros voidaan rakentaa suoraan tietoaltaan Parquet-tiedostojen päälle, ja nykyisin se onnistuu esimerkiksi Databricksillä valtaosin SQL-koodia kirjoittamalla, joten sen rakentaminen ei ole sen vaikeampaa kuin perinteisen SQL-tietokantaan pohjautuvan tietovarastonkaan. Kustannuksissa voidaan säästää, kun sekä tietoallas että tietovarasto voidaan rakentaa saman alustan päälle. On myös syytä miettiä tarkkaan kannattaako enää rakentaa pelkästään perinteistä SQL-tietokantaan perustuvaa tietovarastoa, kun tulevaisuudessa kasvavat datamäärät ja käyttötapaukset saattavat vaatia esimerkiksi reaaliaikaista analytiikkaa tai strukturoimattoman datan prosessointia – ja lakehouse mahdollistaa molemmat samassa paketissa?

Kirjoittaja:
Oskari Tapionsalo, Principal Consultant, Epical
